
开启 Access 日志
| |
1,SLA SLA是Service-Level Agreement的缩写,意思是服务等级协议,一般是协议双方做的彼此承诺,放在运维的领域,很重要的一个结果指标就是系统的SLA,这个是技术向业务做的一个承诺。 系统SLA的定制方法一般有两种,一种是通过时间维度进行测算,另外一种是通过用户请求状态进行测算。
CStor 存储策略
nodeSelector
| |
affinity
| |
resources
| |
tolerations
| |
本文不讲源码,来说说 istio sidecar 配置,从而灵活的控制 sidecar 注入、资源修改等场景。
| |
先来预览一下 istio-sidecar-injector,主要包含 config 和 values
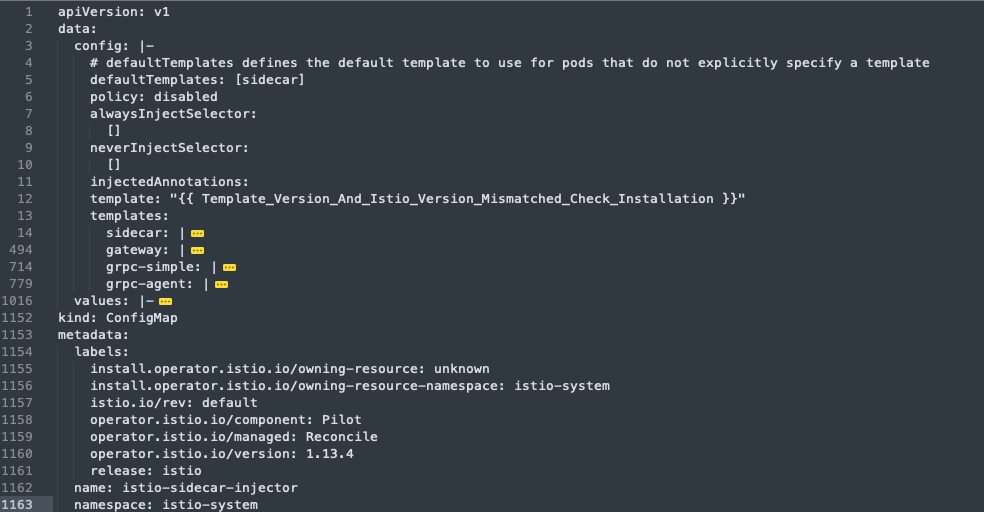
可以看到配置项有 默认模板 defaultTemplates、注入策略 policy、注入选择器 alwaysInjectSelector、 永不注入选择器 neverInjectSelector、injectedAnnotations 和 模板内容 templates 等
关于注入策略(policy)、注入选择器(alwaysInjectSelector、neverInjectSelector)和注入注解(injectedAnnotations)可以查看 Sidecar 自动注入 本文主要来了解 Sidecar 注入的模板,方便后续需要针对Sidecar 的部署调整
| |
根据ca证书和秘钥签发用户证书,kubeadm工具安装是默认生成存放在/etc/kubernetes/pki目录下