深入Istio系列-Pilot Agent
查看监听端口和进程
| |

| |
| |
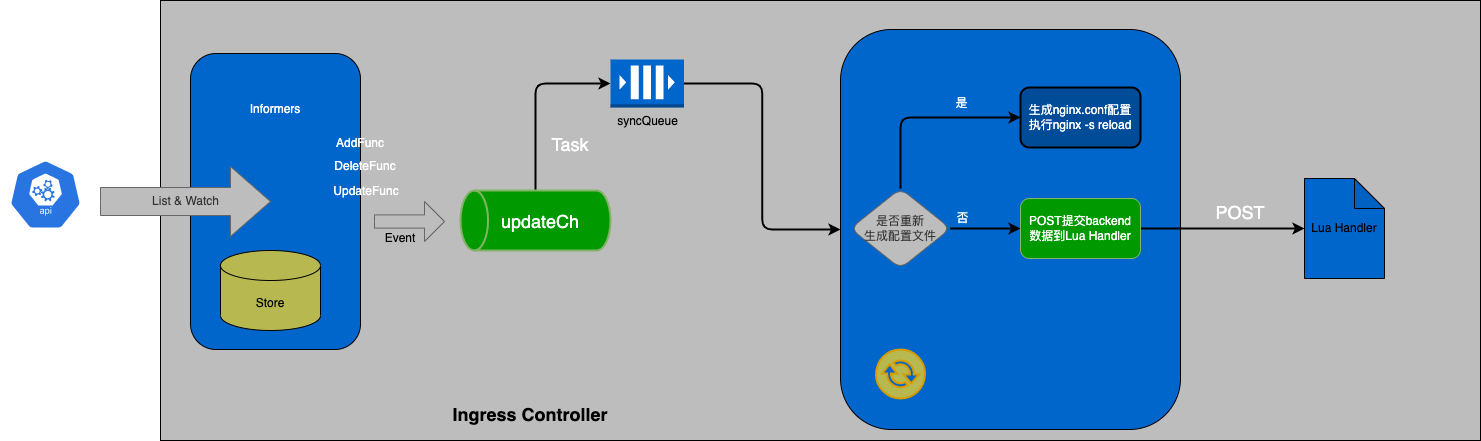
从上面可以看出整个Ingress Nginx Controller Pod 包含两部分 nginx-ingress-controller 和 Nginx
Grafana 实验室的 Mimir 是一个在 AGPLv3 许可下新的时间序列数据库,该工程团队从 Cortex TSDB 中汲取精华,同时降低了复杂性并提高了可扩展性。
根据 Grafana 实验室的测试,Mimir 可以扩展到 10 亿个活跃时间序列和 5000 万个样本/秒的摄取率,该基准测试要求运行一个具有 7000 个 CPU 核心和 30TiB 内存的集群,这已经是我听说的最大、最昂贵的时间序列数据库的公共基准测试了。要重现这样规模的基准测试并不那么容易,幸运的是,在大多数情况下,用户的工作负荷要求要低得多,比较容易模拟。在本文我们将尝试比较 VictoriaMetrics 和 Grafana Mimir 集群在相同硬件上的中等工作负载下运行的性能和资源使用情况。
Prometheus Operator 安装完成后会有很多默认的监控指标,一不注意就大量的报警产生,所以我们非常有必要了解下这些常用的监控指标,有部分指标很有可能对于我们自己的业务可有可无,所以可以适当的进行修改,这里我们就来对常用的几个指标进行简单的说明。
关于 CPU 的 limit 合理性指标。查出最近5分钟,超过25%的 CPU 执行周期受到限制的容器。表达式:
| |
相关指标:
参考:https://istio.io/latest/docs/reference/config/metrics/
对于 HTTP、HTTP/2 和 GRPC 流量,Istio 默认生成以下指标:
istio_requests_total): This is a COUNTER incremented for every request handled by an Istio proxy.istio_request_duration_milliseconds): This is a DISTRIBUTION which measures the duration of requests.istio_request_bytes): This is a DISTRIBUTION which measures HTTP request body sizes.istio_response_bytes): This is a DISTRIBUTION which measures HTTP response body sizes.istio_request_messages_total): This is a COUNTER incremented for every gRPC message sent from a client.istio_response_messages_total): This is a COUNTER incremented for every gRPC message sent from a server.Envoy 的主要目标之一是使网络易于理解。 Envoy 会根据其配置方式产生大量统计信息。一般来说,统计数据(指标)分为三类:
listener、HTTP connection manager(HCM)、TCP proxy filter 等产生。connection pool、router filter、tcp proxy filter等产生。Server 指标信息描述 Envoy 服务器实例的运作情况。服务器正常运行时间或分配的内存量等统计信息。在最简单场景下,单个 Envoy Proxy 通常涉及 Downstream 和 Upstream 统计数据。这两种指标反映了取该 网络节点 的运行情况。来自整个网格的统计数据提供了每个 网络节点 和整体网络健康状况的非常详细的汇总信息。Envoy 的文档对这些指标有一些简单的说明。