概述
在云原生环境中,Fluent Bit 作为轻量级的日志收集器,经常与 Kafka 配合使用来构建高可用的日志处理管道。当遇到 Kafka 生产者 Local: Queue full 错误时,需要通过系统化的监控和分析方法来快速定位问题根因。
本文将详细介绍如何通过 Fluent Bit 的 Prometheus 监控指标来分析和解决 Kafka 队列满的问题。
Fluent Bit 监控配置
启用 Prometheus 监控
首先需要在 Fluent Bit 配置中启用 HTTP 服务器以暴露 Prometheus 指标:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| [SERVICE]
Flush 1
Daemon off
Log_Level info
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
storage.metrics on
[INPUT]
Name tail
Path /var/log/*.log
Tag app.logs
Refresh_Interval 5
[OUTPUT]
Name kafka
Match *
Brokers kafka-broker:9092
Topics sl_monitor_metric_log
Workers 4
Flush 1
queue_full_retries 10
rdkafka.batch.size 16384
rdkafka.linger.ms 5
rdkafka.compression.type snappy
|
Prometheus 抓取配置
在 Prometheus 配置文件中添加 Fluent Bit 的抓取任务:
1
2
3
4
5
6
| scrape_configs:
- job_name: 'fluent-bit'
static_configs:
- targets: ['fluent-bit:2020']
metrics_path: '/api/v1/metrics/prometheus'
scrape_interval: 15s
|
关键监控指标
输入端指标
fluentbit_input_records_total: 输入记录总数fluentbit_input_bytes_total: 输入字节总数
输出端指标
fluentbit_output_proc_records_total: 成功处理的输出记录总数fluentbit_output_errors_total: 输出错误总数fluentbit_output_dropped_records_total: 丢弃的记录总数fluentbit_output_retries_total: 重试次数总数fluentbit_output_retries_failed_total: 重试失败次数总数
问题分析方法
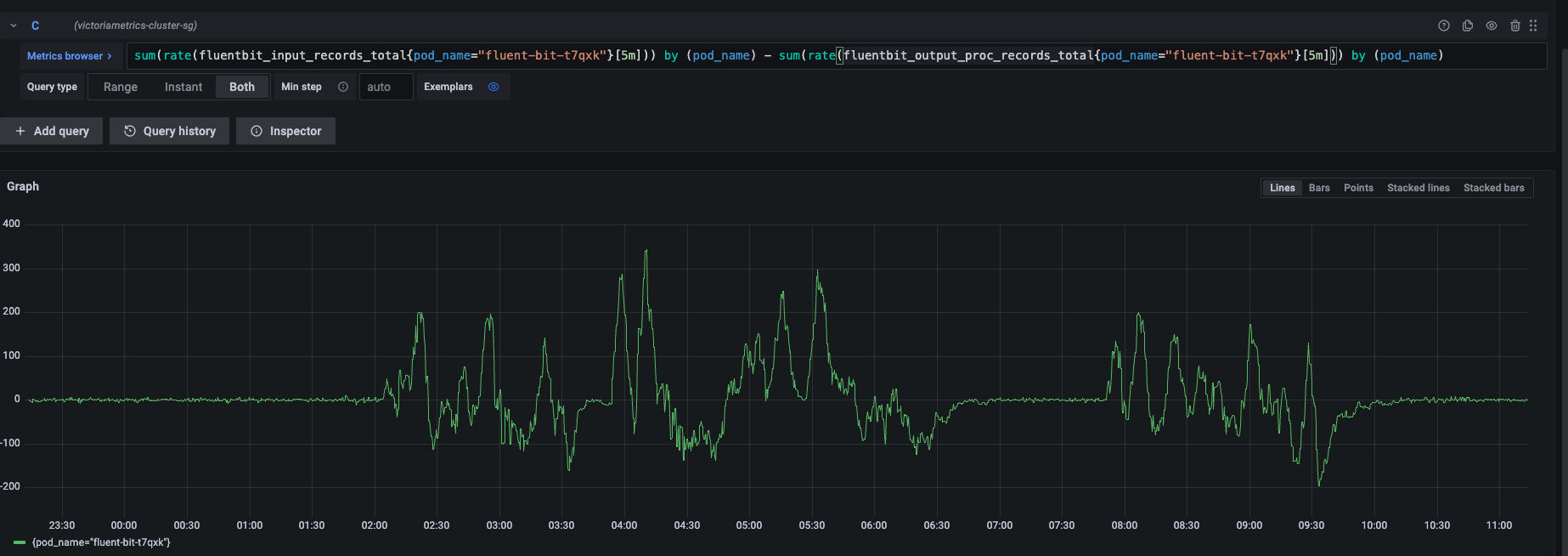
场景分析:输入正常,消息积压,输出输入比下降,成功率正常
当遇到以下现象时:
- 输入速率正常
- 消息存在积压
- 输出输入比下降(输出速率 < 输入速率)
- 输出成功率正常
fluentbit_output_errors_total 没有增加
这通常表明系统处于吞吐量瓶颈状态,输出端处理能力不足以匹配输入端的数据量。
可能原因分析
1. Kafka 集群吞吐量限制
- Kafka broker 处理速度达到上限
- 磁盘 I/O 或网络带宽成为瓶颈
- 分区数不足,限制了并行写入能力
- 副本同步延迟影响整体吞吐量
2. Fluent Bit 输出配置限制
Workers 数量不足,无法充分利用并发能力Flush 间隔过大,导致批处理效率低- 缓冲区大小限制了批量发送能力
- 单个输出插件实例的处理能力上限
3. 网络传输瓶颈
- 网络带宽不足以支撑当前数据量
- 网络延迟导致每次传输耗时增加
- TCP 连接数限制影响并发传输
- 负载均衡器或代理的性能限制
4. Kafka 生产者性能配置
- 批处理大小
batch.size 设置过小 - 等待时间
linger.ms 配置不当 - 压缩算法选择影响处理速度
- 确认机制
acks 设置过于保守
Prometheus 查询语句
计算消息堆积差值
1
2
3
4
5
6
7
8
| # 输入速率
sum(rate(fluentbit_input_records_total[5m])) by (instance)
# 输出成功速率
sum(rate(fluentbit_output_proc_records_total{name="kafka"}[5m])) by (instance)
# 堆积差值(输入 - 输出)
sum(rate(fluentbit_input_records_total{pod_name="fluent-bit-t7qxk"}[5m])) by (pod_name) - sum(rate(fluentbit_output_proc_records_total{pod_name="fluent-bit-t7qxk"}[5m])) by (pod_name)
|
计算输出输入比
1
2
3
4
5
6
7
8
9
10
11
| # 输出输入比(吞吐量比率)
sum(rate(fluentbit_output_proc_records_total{name="kafka"}[5m])) by (instance) /
sum(rate(fluentbit_input_records_total[5m])) by (instance) * 100
# 输出成功率(用于验证输出质量)
sum(rate(fluentbit_output_proc_records_total{name="kafka"}[5m])) by (instance) /
(
sum(rate(fluentbit_output_proc_records_total{name="kafka"}[5m])) by (instance) +
sum(rate(fluentbit_output_errors_total{name="kafka"}[5m])) by (instance) +
sum(rate(fluentbit_output_dropped_records_total{name="kafka"}[5m])) by (instance)
) * 100
|
监控队列长度趋势
1
2
| # 通过累积差值估算队列积压
sum(increase(fluentbit_input_records_total{pod_name="fluent-bit-t7qxk"}[5m])) - sum(increase(fluentbit_output_proc_records_total{pod_name="fluent-bit-t7qxk"}[5m]))
|
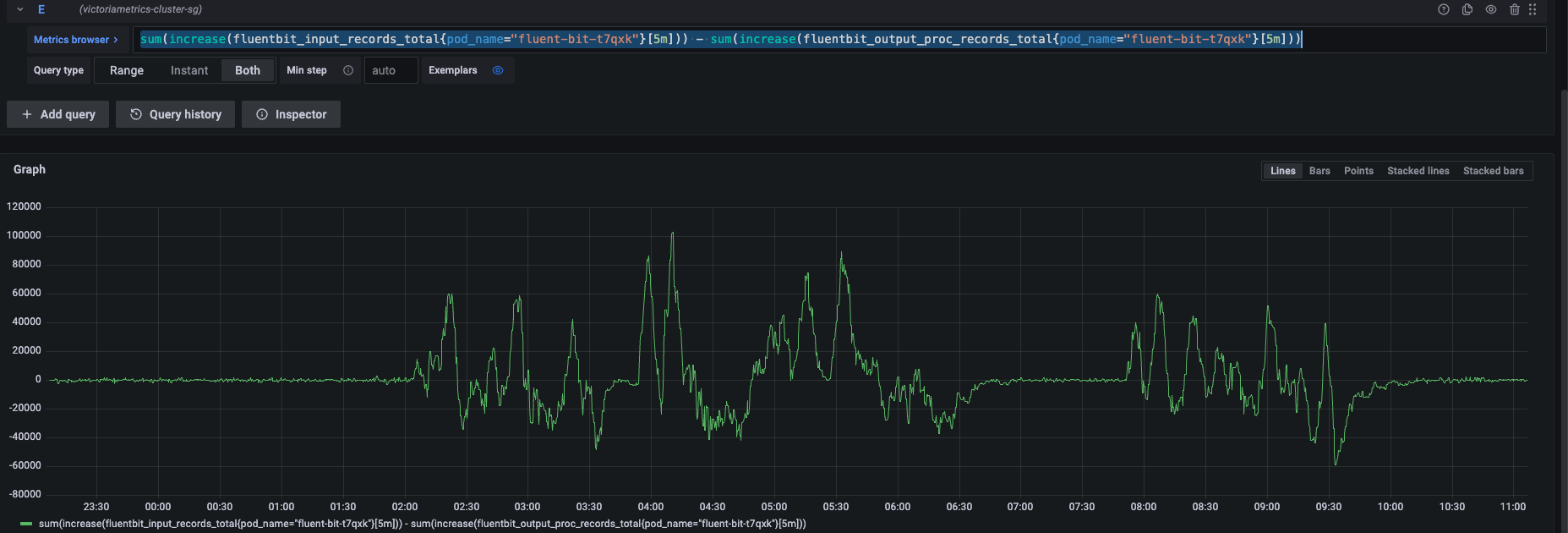
监控重试情况
1
2
3
4
5
| # 重试速率
rate(fluentbit_output_retries_total{name="kafka"}[5m])
# 重试失败速率
rate(fluentbit_output_retries_failed_total{name="kafka"}[5m])
|
故障排查步骤
1. 检查 Kafka 集群状态
1
2
3
4
5
6
7
8
| # 检查 Kafka 集群健康状态
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic sl_monitor_metric_log
# 检查消费者组延迟
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group your-consumer-group
# 检查 Kafka 集群负载
kafka-run-class.sh kafka.tools.JmxTool --object-name kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec
|
2. 分析 Fluent Bit 指标
1
2
3
4
5
| # 实时查看 Fluent Bit 指标
curl -s http://fluent-bit:2020/api/v1/metrics/prometheus | grep -E "(input_records|output_proc_records|output_errors)"
# 查看当前队列状态
curl -s http://fluent-bit:2020/api/v1/metrics | jq '.'
|
3. 检查系统资源
1
2
3
4
5
6
7
8
| # 检查 CPU 和内存使用情况
top -p $(pgrep fluent-bit)
# 检查网络连接状态
netstat -an | grep :9092
# 检查磁盘 I/O
iostat -x 1 5
|
优化建议
Fluent Bit 配置优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| [OUTPUT]
Name kafka
Match *
Brokers kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
Topics sl_monitor_metric_log
# 性能优化参数
Workers 8 # 增加工作线程
Flush 1 # 减少刷新间隔
queue_full_retries 20 # 增加重试次数
# Kafka 生产者优化
rdkafka.batch.size 32768 # 增加批次大小
rdkafka.linger.ms 10 # 适当增加等待时间
rdkafka.compression.type lz4 # 使用高效压缩
rdkafka.acks 1 # 平衡性能和可靠性
rdkafka.retries 5 # 设置重试次数
rdkafka.retry.backoff.ms 100 # 重试间隔
# 缓冲区配置
rdkafka.queue.buffering.max.messages 100000
rdkafka.queue.buffering.max.kbytes 1048576
|
Kafka 集群优化
- 增加分区数:提高并行处理能力
- 调整副本因子:平衡可靠性和性能
- 优化 broker 配置:调整
num.network.threads 和 num.io.threads - 监控磁盘使用:确保有足够的磁盘空间和 I/O 性能
告警配置
Prometheus 告警规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| groups:
- name: fluent-bit-kafka
rules:
- alert: FluentBitMessageBacklog
expr: |
(
sum(rate(fluentbit_input_records_total[5m])) by (instance) -
sum(rate(fluentbit_output_proc_records_total{name="kafka"}[5m])) by (instance)
) > 100
for: 2m
labels:
severity: warning
annotations:
summary: "Fluent Bit 消息积压 (实例: {{ $labels.instance }})"
description: "消息积压速率: {{ $value }} records/sec,持续时间超过 2 分钟"
- alert: FluentBitThroughputRatioLow
expr: |
(
sum(rate(fluentbit_output_proc_records_total{name="kafka"}[5m])) by (instance) /
sum(rate(fluentbit_input_records_total[5m])) by (instance) * 100
) < 80
for: 2m
labels:
severity: warning
annotations:
summary: "Fluent Bit 输出输入比过低 (实例: {{ $labels.instance }})"
description: "当前输出输入比: {{ $value }}%,低于 80% 阈值,存在消息积压风险"
- alert: FluentBitOutputSuccessRateDown
expr: |
(
sum(rate(fluentbit_output_proc_records_total{name="kafka"}[5m])) by (instance) /
(
sum(rate(fluentbit_output_proc_records_total{name="kafka"}[5m])) by (instance) +
sum(rate(fluentbit_output_errors_total{name="kafka"}[5m])) by (instance) +
sum(rate(fluentbit_output_dropped_records_total{name="kafka"}[5m])) by (instance)
) * 100
) < 95
for: 2m
labels:
severity: critical
annotations:
summary: "Fluent Bit 输出成功率下降 (实例: {{ $labels.instance }})"
description: "当前成功率: {{ $value }}%,低于 95% 阈值"
- alert: FluentBitHighRetryRate
expr: rate(fluentbit_output_retries_total{name="kafka"}[5m]) > 10
for: 1m
labels:
severity: warning
annotations:
summary: "Fluent Bit Kafka 输出重试率过高"
description: "重试率: {{ $value }} retries/sec,可能存在连接或性能问题"
- alert: FluentBitKafkaConnectionIssue
expr: increase(fluentbit_output_retries_failed_total{name="kafka"}[5m]) > 50
for: 1m
labels:
severity: critical
annotations:
summary: "Fluent Bit Kafka 连接异常"
description: "5分钟内重试失败次数: {{ $value }},可能存在网络或 Kafka 集群问题"
|
实时监控命令
监控脚本示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| #!/bin/bash
# fluent-bit-monitor.sh
echo "=== Fluent Bit Kafka 监控 ==="
echo "时间: $(date)"
echo
# 获取基础指标
METRICS=$(curl -s http://localhost:2020/api/v1/metrics/prometheus)
# 输入速率
INPUT_RATE=$(echo "$METRICS" | grep 'fluentbit_input_records_total' | tail -1 | awk '{print $2}')
echo "输入记录总数: $INPUT_RATE"
# 输出成功数
OUTPUT_SUCCESS=$(echo "$METRICS" | grep 'fluentbit_output_proc_records_total.*kafka' | awk '{print $2}')
echo "输出成功总数: $OUTPUT_SUCCESS"
# 输出错误数
OUTPUT_ERRORS=$(echo "$METRICS" | grep 'fluentbit_output_errors_total.*kafka' | awk '{print $2}')
echo "输出错误总数: $OUTPUT_ERRORS"
# 重试次数
RETRIES=$(echo "$METRICS" | grep 'fluentbit_output_retries_total.*kafka' | awk '{print $2}')
echo "重试总次数: $RETRIES"
echo
echo "=== Kafka 集群状态 ==="
kafka-broker-api-versions.sh --bootstrap-server localhost:9092 2>/dev/null && echo "Kafka 集群连接正常" || echo "Kafka 集群连接异常"
|
总结
通过系统化的监控和分析方法,我们可以快速定位 Fluent Bit Kafka 队列满的问题:
- 启用完整的监控体系:配置 Prometheus 监控和告警
- 分析关键指标:重点关注输入输出速率差值和成功率
- 系统化排查:从 Kafka 集群、网络、配置等多个维度分析
- 持续优化:根据监控数据调整配置参数
- 预防性措施:建立完善的告警机制
记住,大多数队列满的问题都是性能瓶颈导致的,而不是错误。通过合理的配置优化和容量规划,可以有效避免此类问题的发生。