# A comma-separated list of components to run. The default value 'all' runs Loki# in single binary mode. The value 'read' is an alias to run only read-path# related components such as the querier and query-frontend, but all in the same# process. The value 'write' is an alias to run only write-path related# components such as the distributor and compactor, but all in the same process.# Supported values: all, compactor, distributor, ingester, querier,# query-scheduler, ingester-querier, query-frontend, index-gateway, ruler,# table-manager, read, write. A full list of available targets can be printed# when running Loki with the '-list-targets' command line flag.# CLI flag: -target[target:<string> | default = "all"]# Enables authentication through the X-Scope-OrgID header, which must be present# if true. If false, the OrgID will always be set to 'fake'.# CLI flag: -auth.enabled[auth_enabled:<boolean> | default = true]# The amount of virtual memory in bytes to reserve as ballast in order to# optimize garbage collection. Larger ballasts result in fewer garbage# collection passes, reducing CPU overhead at the cost of heap size. The ballast# will not consume physical memory, because it is never read from. It will,# however, distort metrics, because it is counted as live memory.# CLI flag: -config.ballast-bytes[ballast_bytes:<int> | default = 0]# Configures the server of the launched module(s).[server:<server>]# Configures the distributor.[distributor:<distributor>]# Configures the querier. Only appropriate when running all modules or just the# querier.[querier:<querier>]# The query_scheduler block configures the Loki query scheduler. When configured# it separates the tenant query queues from the query-frontend.[query_scheduler:<query_scheduler>]# The frontend block configures the Loki query-frontend.[frontend:<frontend>]# The query_range block configures the query splitting and caching in the Loki# query-frontend.[query_range:<query_range>]# The ruler block configures the Loki ruler.[ruler:<ruler>]# The ingester_client block configures how the distributor will connect to# ingesters. Only appropriate when running all components, the distributor, or# the querier.[ingester_client:<ingester_client>]# The ingester block configures the ingester and how the ingester will register# itself to a key value store.[ingester:<ingester>]# The index_gateway block configures the Loki index gateway server, responsible# for serving index queries without the need to constantly interact with the# object store.[index_gateway:<index_gateway>]# The storage_config block configures one of many possible stores for both the# index and chunks. Which configuration to be picked should be defined in# schema_config block.[storage_config:<storage_config>]# The chunk_store_config block configures how chunks will be cached and how long# to wait before saving them to the backing store.[chunk_store_config:<chunk_store_config>]# Configures the chunk index schema and where it is stored.[schema_config:<schema_config>]# The compactor block configures the compactor component, which compacts index# shards for performance.[compactor:<compactor>]# The limits_config block configures global and per-tenant limits in Loki.[limits_config:<limits_config>]# The frontend_worker configures the worker - running within the Loki querier -# picking up and executing queries enqueued by the query-frontend.[frontend_worker:<frontend_worker>]# The table_manager block configures the table manager for retention.[table_manager:<table_manager>]# Configuration for memberlist client. Only applies if the selected kvstore is# memberlist.# # When a memberlist config with atleast 1 join_members is defined, kvstore of# type memberlist is automatically selected for all the components that require# a ring unless otherwise specified in the component's configuration section.[memberlist:<memberlist>]# Configuration for 'runtime config' module, responsible for reloading runtime# configuration file.[runtime_config:<runtime_config>]# Configuration for tracing.[tracing:<tracing>]# Configuration for usage report.[analytics:<analytics>]# Common configuration to be shared between multiple modules. If a more specific# configuration is given in other sections, the related configuration within# this section will be ignored.[common:<common>]# How long to wait between SIGTERM and shutdown. After receiving SIGTERM, Loki# will report 503 Service Unavailable status via /ready endpoint.# CLI flag: -shutdown-delay[shutdown_delay:<duration> | default = 0s]
# 定义后,指定前缀将出现在端点路径的前面[path_prefix:<string> | default = ""]# 不同 Loki 组件使用的公共存储配置storage:# 支持 AWS S3 协议类型的对象存储,比如minio# The s3_storage_config block configures the connection to Amazon S3 object# storage backend.# The CLI flags prefix for this block configuration is: common[s3:<s3_storage_config>]# The gcs_storage_config block configures the connection to Google Cloud# Storage object storage backend.# The CLI flags prefix for this block configuration is: common.storage#Google Cloud Storage 配置[gcs:<gcs_storage_config>]# The azure_storage_config block configures the connection to Azure object# storage backend.# The CLI flags prefix for this block configuration is: common.storage# Azure Storage 对象存储配置[azure:<azure_storage_config>]# The alibabacloud_storage_config block configures the connection to Alibaba# Cloud Storage object storage backend.# 阿里云 OSS 对象存储配置[alibabacloud:<alibabacloud_storage_config>]# The bos_storage_config block configures the connection to Baidu Object# Storage (BOS) object storage backend.# The CLI flags prefix for this block configuration is: common.# 百度云 OSS 对象存储配置[bos:<bos_storage_config>]# The swift_storage_config block configures the connection to OpenStack Object# Storage (Swift) object storage backend.# The CLI flags prefix for this block configuration is: common.storage# OpenStack 对象存储配置[swift:<swift_storage_config>]# 本地文件系统配置filesystem:# Directory to store chunks in.# CLI flag: -common.storage.filesystem.chunk-directory[chunks_directory:<string> | default = ""]# Directory to store rules in.# CLI flag: -common.storage.filesystem.rules-directory[rules_directory:<string> | default = ""]hedging:# If set to a non-zero value a second request will be issued at the provided# duration. Default is 0 (disabled)# CLI flag: -common.storage.hedge-requests-at[at:<duration> | default = 0s]# The maximum of hedge requests allowed.# CLI flag: -common.storage.hedge-requests-up-to[up_to:<int> | default = 2]# The maximum of hedge requests allowed per seconds.# CLI flag: -common.storage.hedge-max-per-second[max_per_second:<int> | default = 5]# 如果为 true,则 ingester、compactor 和 query_scheduler 的 ring tokens 将保存到 path_prefix 目录中的文件中。如果将其设置为 true 且 path_prefix 前缀为空,Loki 将出错。[persist_tokens:<boolean>]# 传入到 ingester 组件的数据副本数[replication_factor:<int>]# 所有 Loki rings 使用的通用 ring 配置。# 如果指定了通用的 ring 环,则其值用于定义任何未定义的 ring 值。# 例如,当公共部分中定义的 `heartbeat_period`,但是 distributor 的 ring 本身没有配置 `heartbeat_period`,则公共配置生效。ring:kvstore:# Backend storage to use for the ring. Supported values are: consul, etcd,# inmemory, memberlist, multi.# CLI flag: -common.storage.ring.store[store:<string> | default = "consul"]# The prefix for the keys in the store. Should end with a /.# CLI flag: -common.storage.ring.prefix[prefix:<string> | default = "collectors/"]# Configuration for a Consul client. Only applies if the selected kvstore is# consul.# The CLI flags prefix for this block configuration is: common.storage.ring[consul:<consul>]# Configuration for an ETCD v3 client. Only applies if the selected kvstore# is etcd.# The CLI flags prefix for this block configuration is: common.storage.ring[etcd:<etcd>]multi:# Primary backend storage used by multi-client.# CLI flag: -common.storage.ring.multi.primary[primary:<string> | default = ""]# Secondary backend storage used by multi-client.# CLI flag: -common.storage.ring.multi.secondary[secondary:<string> | default = ""]# Mirror writes to secondary store.# CLI flag: -common.storage.ring.multi.mirror-enabled[mirror_enabled:<boolean> | default = false]# Timeout for storing value to secondary store.# CLI flag: -common.storage.ring.multi.mirror-timeout[mirror_timeout:<duration> | default = 2s]# Period at which to heartbeat to the ring. 0 = disabled.# CLI flag: -common.storage.ring.heartbeat-period[heartbeat_period:<duration> | default = 15s]# The heartbeat timeout after which compactors are considered unhealthy within# the ring. 0 = never (timeout disabled).# CLI flag: -common.storage.ring.heartbeat-timeout[heartbeat_timeout:<duration> | default = 1m]# File path where tokens are stored. If empty, tokens are not stored at# shutdown and restored at startup.# CLI flag: -common.storage.ring.tokens-file-path[tokens_file_path:<string> | default = ""]# True to enable zone-awareness and replicate blocks across different# availability zones.# CLI flag: -common.storage.ring.zone-awareness-enabled[zone_awareness_enabled:<boolean> | default = false]# Instance ID to register in the ring.# CLI flag: -common.storage.ring.instance-id[instance_id:<string> | default = "<hostname>"]# Name of network interface to read address from.# CLI flag: -common.storage.ring.instance-interface-names[instance_interface_names:<list of strings> | default = [<private network interfaces>]]# Port to advertise in the ring (defaults to server.grpc-listen-port).# CLI flag: -common.storage.ring.instance-port[instance_port:<int> | default = 0]# IP address to advertise in the ring.# CLI flag: -common.storage.ring.instance-addr[instance_addr:<string> | default = ""]# The availability zone where this instance is running. Required if# zone-awareness is enabled.# CLI flag: -common.storage.ring.instance-availability-zone[instance_availability_zone:<string> | default = ""][instance_interface_names:<list of strings>][instance_addr:<string> | default = ""]# the http address of the compactor in the form http://host:port# CLI flag: -common.compactor-address[compactor_address:<string> | default = ""]# the grpc address of the compactor in the form host:port# CLI flag: -common.compactor-grpc-address[compactor_grpc_address:<string> | default = ""]
dynamodb:# DynamoDB endpoint URL with escaped Key and Secret encoded. If only region is# specified as a host, proper endpoint will be deduced. Use# inmemory:///<table-name> to use a mock in-memory implementation.# CLI flag: -dynamodb.url[dynamodb_url:<url>]# DynamoDB table management requests per second limit.# CLI flag: -dynamodb.api-limit[api_limit:<float> | default = 2]# DynamoDB rate cap to back off when throttled.# CLI flag: -dynamodb.throttle-limit[throttle_limit:<float> | default = 10]metrics:# Use metrics-based autoscaling, via this query URL# CLI flag: -metrics.url[url:<string> | default = ""]# Queue length above which we will scale up capacity# CLI flag: -metrics.target-queue-length[target_queue_length:<int> | default = 100000]# Scale up capacity by this multiple# CLI flag: -metrics.scale-up-factor[scale_up_factor:<float> | default = 1.3]# Ignore throttling below this level (rate per second)# CLI flag: -metrics.ignore-throttle-below[ignore_throttle_below:<float> | default = 1]# query to fetch ingester queue length# CLI flag: -metrics.queue-length-query[queue_length_query:<string> | default = "sum(avg_over_time(cortex_ingester_flush_queue_length{job=\"cortex/ingester\"}[2m]))"]# query to fetch throttle rates per table# CLI flag: -metrics.write-throttle-query[write_throttle_query:<string> | default = "sum(rate(cortex_dynamo_throttled_total{operation=\"DynamoDB.BatchWriteItem\"}[1m])) by (table) > 0"]# query to fetch write capacity usage per table# CLI flag: -metrics.usage-query[write_usage_query:<string> | default = "sum(rate(cortex_dynamo_consumed_capacity_total{operation=\"DynamoDB.BatchWriteItem\"}[15m])) by (table) > 0"]# query to fetch read capacity usage per table# CLI flag: -metrics.read-usage-query[read_usage_query:<string> | default = "sum(rate(cortex_dynamo_consumed_capacity_total{operation=\"DynamoDB.QueryPages\"}[1h])) by (table) > 0"]# query to fetch read errors per table# CLI flag: -metrics.read-error-query[read_error_query:<string> | default = "sum(increase(cortex_dynamo_failures_total{operation=\"DynamoDB.QueryPages\",error=\"ProvisionedThroughputExceededException\"}[1m])) by (table) > 0"]# Number of chunks to group together to parallelise fetches (zero to disable)# CLI flag: -dynamodb.chunk-gang-size[chunk_gang_size:<int> | default = 10]# Max number of chunk-get operations to start in parallel# CLI flag: -dynamodb.chunk.get-max-parallelism[chunk_get_max_parallelism:<int> | default = 32]backoff_config:# Minimum backoff time# CLI flag: -dynamodb.min-backoff[min_period:<duration> | default = 100ms]# Maximum backoff time# CLI flag: -dynamodb.max-backoff[max_period:<duration> | default = 50s]# Maximum number of times to retry an operation# CLI flag: -dynamodb.max-retries[max_retries:<int> | default = 20]# KMS key used for encrypting DynamoDB items. DynamoDB will use an Amazon# owned KMS key if not provided.# CLI flag: -dynamodb.kms-key-id[kms_key_id:<string> | default = ""]# S3 endpoint URL with escaped Key and Secret encoded. If only region is# specified as a host, proper endpoint will be deduced. Use# inmemory:///<bucket-name> to use a mock in-memory implementation.# CLI flag: -s3.url[s3:<url>]# Set this to `true` to force the request to use path-style addressing.# CLI flag: -s3.force-path-style[s3forcepathstyle:<boolean> | default = false]# Comma separated list of bucket names to evenly distribute chunks over.# Overrides any buckets specified in s3.url flag# CLI flag: -s3.buckets[bucketnames:<string> | default = ""]# S3 Endpoint to connect to.# CLI flag: -s3.endpoint[endpoint:<string> | default = ""]# AWS region to use.# CLI flag: -s3.region[region:<string> | default = ""]# AWS Access Key ID# CLI flag: -s3.access-key-id[access_key_id:<string> | default = ""]# AWS Secret Access Key# CLI flag: -s3.secret-access-key[secret_access_key:<string> | default = ""]# AWS Session Token# CLI flag: -s3.session-token[session_token:<string> | default = ""]# Disable https on s3 connection.# CLI flag: -s3.insecure[insecure:<boolean> | default = false]# Enable AWS Server Side Encryption [Deprecated: Use .sse instead. if# s3.sse-encryption is enabled, it assumes .sse.type SSE-S3]# CLI flag: -s3.sse-encryption[sse_encryption:<boolean> | default = false]http_config:# The maximum amount of time an idle connection will be held open.# CLI flag: -s3.http.idle-conn-timeout[idle_conn_timeout:<duration> | default = 1m30s]# If non-zero, specifies the amount of time to wait for a server's response# headers after fully writing the request.# CLI flag: -s3.http.response-header-timeout[response_header_timeout:<duration> | default = 0s]# Set to true to skip verifying the certificate chain and hostname.# CLI flag: -s3.http.insecure-skip-verify[insecure_skip_verify:<boolean> | default = false]# Path to the trusted CA file that signed the SSL certificate of the S3# endpoint.# CLI flag: -s3.http.ca-file[ca_file:<string> | default = ""]# The signature version to use for authenticating against S3. Supported values# are: v4, v2.# CLI flag: -s3.signature-version[signature_version:<string> | default = "v4"]# The S3 storage class which objects will use. Supported values are: GLACIER,# DEEP_ARCHIVE, GLACIER_IR, INTELLIGENT_TIERING, ONEZONE_IA, OUTPOSTS,# REDUCED_REDUNDANCY, STANDARD, STANDARD_IA.# CLI flag: -s3.storage-class[storage_class:<string> | default = "STANDARD"]sse:# Enable AWS Server Side Encryption. Supported values: SSE-KMS, SSE-S3.# CLI flag: -s3.sse.type[type:<string> | default = ""]# KMS Key ID used to encrypt objects in S3# CLI flag: -s3.sse.kms-key-id[kms_key_id:<string> | default = ""]# KMS Encryption Context used for object encryption. It expects JSON formatted# string.# CLI flag: -s3.sse.kms-encryption-context[kms_encryption_context:<string> | default = ""]# Configures back off when S3 get Object.backoff_config:# Minimum backoff time when s3 get Object# CLI flag: -s3.min-backoff[min_period:<duration> | default = 100ms]# Maximum backoff time when s3 get Object# CLI flag: -s3.max-backoff[max_period:<duration> | default = 3s]# Maximum number of times to retry when s3 get Object# CLI flag: -s3.max-retries[max_retries:<int> | default = 5]
ring:kvstore:# Backend storage to use for the ring. Supported values are: consul, etcd,# inmemory, memberlist, multi.# CLI flag: -distributor.ring.store[store:<string> | default = "consul"]# The prefix for the keys in the store. Should end with a /.# CLI flag: -distributor.ring.prefix[prefix:<string> | default = "collectors/"]# Configuration for a Consul client. Only applies if the selected kvstore is# consul.# The CLI flags prefix for this block configuration is: distributor.ring[consul:<consul>]# Configuration for an ETCD v3 client. Only applies if the selected kvstore# is etcd.# The CLI flags prefix for this block configuration is: distributor.ring[etcd:<etcd>]multi:# Primary backend storage used by multi-client.# CLI flag: -distributor.ring.multi.primary[primary:<string> | default = ""]# Secondary backend storage used by multi-client.# CLI flag: -distributor.ring.multi.secondary[secondary:<string> | default = ""]# Mirror writes to secondary store.# CLI flag: -distributor.ring.multi.mirror-enabled[mirror_enabled:<boolean> | default = false]# Timeout for storing value to secondary store.# CLI flag: -distributor.ring.multi.mirror-timeout[mirror_timeout:<duration> | default = 2s]# Period at which to heartbeat to the ring. 0 = disabled.# CLI flag: -distributor.ring.heartbeat-period[heartbeat_period:<duration> | default = 5s]# The heartbeat timeout after which distributors are considered unhealthy# within the ring. 0 = never (timeout disabled).# CLI flag: -distributor.ring.heartbeat-timeout[heartbeat_timeout:<duration> | default = 1m]# Name of network interface to read address from.# CLI flag: -distributor.ring.instance-interface-names[instance_interface_names:<list of strings> | default = [<private network interfaces>]]rate_store:# The max number of concurrent requests to make to ingester stream apis# CLI flag: -distributor.rate-store.max-request-parallelism[max_request_parallelism:<int> | default = 200]# The interval on which distributors will update current stream rates from# ingesters# CLI flag: -distributor.rate-store.stream-rate-update-interval[stream_rate_update_interval:<duration> | default = 1s]# Timeout for communication between distributors and any given ingester when# updating rates# CLI flag: -distributor.rate-store.ingester-request-timeout[ingester_request_timeout:<duration> | default = 500ms]
# Configures how the lifecycle of the ingester will operate and where it will# register for discovery.lifecycler:ring:kvstore:# Backend storage to use for the ring. Supported values are: consul, etcd,# inmemory, memberlist, multi.# CLI flag: -ring.store[store:<string> | default = "consul"]# The prefix for the keys in the store. Should end with a /.# CLI flag: -ring.prefix[prefix:<string> | default = "collectors/"]# Configuration for a Consul client. Only applies if the selected kvstore# is consul.[consul:<consul>]# Configuration for an ETCD v3 client. Only applies if the selected# kvstore is etcd.[etcd:<etcd>]multi:# Primary backend storage used by multi-client.# CLI flag: -multi.primary[primary:<string> | default = ""]# Secondary backend storage used by multi-client.# CLI flag: -multi.secondary[secondary:<string> | default = ""]# Mirror writes to secondary store.# CLI flag: -multi.mirror-enabled[mirror_enabled:<boolean> | default = false]# Timeout for storing value to secondary store.# CLI flag: -multi.mirror-timeout[mirror_timeout:<duration> | default = 2s]# The heartbeat timeout after which ingesters are skipped for reads/writes.# 0 = never (timeout disabled).# CLI flag: -ring.heartbeat-timeout[heartbeat_timeout:<duration> | default = 1m]# The number of ingesters to write to and read from.# CLI flag: -distributor.replication-factor[replication_factor:<int> | default = 3]# True to enable the zone-awareness and replicate ingested samples across# different availability zones.# CLI flag: -distributor.zone-awareness-enabled[zone_awareness_enabled:<boolean> | default = false]# Comma-separated list of zones to exclude from the ring. Instances in# excluded zones will be filtered out from the ring.# CLI flag: -distributor.excluded-zones[excluded_zones:<string> | default = ""]# Number of tokens for each ingester.# CLI flag: -ingester.num-tokens[num_tokens:<int> | default = 128]# Period at which to heartbeat to consul. 0 = disabled.# CLI flag: -ingester.heartbeat-period[heartbeat_period:<duration> | default = 5s]# Heartbeat timeout after which instance is assumed to be unhealthy. 0 =# disabled.# CLI flag: -ingester.heartbeat-timeout[heartbeat_timeout:<duration> | default = 1m]# Observe tokens after generating to resolve collisions. Useful when using# gossiping ring.# CLI flag: -ingester.observe-period[observe_period:<duration> | default = 0s]# Period to wait for a claim from another member; will join automatically# after this.# CLI flag: -ingester.join-after[join_after:<duration> | default = 0s]# Minimum duration to wait after the internal readiness checks have passed but# before succeeding the readiness endpoint. This is used to slowdown# deployment controllers (eg. Kubernetes) after an instance is ready and# before they proceed with a rolling update, to give the rest of the cluster# instances enough time to receive ring updates.# CLI flag: -ingester.min-ready-duration[min_ready_duration:<duration> | default = 15s]# Name of network interface to read address from.# CLI flag: -ingester.lifecycler.interface[interface_names:<list of strings> | default = [<private network interfaces>]]# Duration to sleep for before exiting, to ensure metrics are scraped.# CLI flag: -ingester.final-sleep[final_sleep:<duration> | default = 0s]# File path where tokens are stored. If empty, tokens are not stored at# shutdown and restored at startup.# CLI flag: -ingester.tokens-file-path[tokens_file_path:<string> | default = ""]# The availability zone where this instance is running.# CLI flag: -ingester.availability-zone[availability_zone:<string> | default = ""]# Unregister from the ring upon clean shutdown. It can be useful to disable# for rolling restarts with consistent naming in conjunction with# -distributor.extend-writes=false.# CLI flag: -ingester.unregister-on-shutdown[unregister_on_shutdown:<boolean> | default = true]# When enabled the readiness probe succeeds only after all instances are# ACTIVE and healthy in the ring, otherwise only the instance itself is# checked. This option should be disabled if in your cluster multiple# instances can be rolled out simultaneously, otherwise rolling updates may be# slowed down.# CLI flag: -ingester.readiness-check-ring-health[readiness_check_ring_health:<boolean> | default = true]# IP address to advertise in the ring.# CLI flag: -ingester.lifecycler.addr[address:<string> | default = ""]# port to advertise in consul (defaults to server.grpc-listen-port).# CLI flag: -ingester.lifecycler.port[port:<int> | default = 0]# ID to register in the ring.# CLI flag: -ingester.lifecycler.ID[id:<string> | default = "<hostname>"]# Number of times to try and transfer chunks before falling back to flushing. If# set to 0 or negative value, transfers are disabled.# CLI flag: -ingester.max-transfer-retries[max_transfer_retries:<int> | default = 0]# How many flushes can happen concurrently from each stream.# CLI flag: -ingester.concurrent-flushes[concurrent_flushes:<int> | default = 32]# How often should the ingester see if there are any blocks to flush.# CLI flag: -ingester.flush-check-period[flush_check_period:<duration> | default = 30s]# The timeout before a flush is cancelled.# CLI flag: -ingester.flush-op-timeout[flush_op_timeout:<duration> | default = 10m]# How long chunks should be retained in-memory after they've been flushed.# CLI flag: -ingester.chunks-retain-period[chunk_retain_period:<duration> | default = 0s]# How long chunks should sit in-memory with no updates before being flushed if# they don't hit the max block size. This means that half-empty chunks will# still be flushed after a certain period as long as they receive no further# activity.# CLI flag: -ingester.chunks-idle-period[chunk_idle_period:<duration> | default = 30m]# The targeted _uncompressed_ size in bytes of a chunk block When this threshold# is exceeded the head block will be cut and compressed inside the chunk.# CLI flag: -ingester.chunks-block-size[chunk_block_size:<int> | default = 262144]# A target _compressed_ size in bytes for chunks. This is a desired size not an# exact size, chunks may be slightly bigger or significantly smaller if they get# flushed for other reasons (e.g. chunk_idle_period). A value of 0 creates# chunks with a fixed 10 blocks, a non zero value will create chunks with a# variable number of blocks to meet the target size.# CLI flag: -ingester.chunk-target-size[chunk_target_size:<int> | default = 1572864]# The algorithm to use for compressing chunk. (none, gzip, lz4-64k, snappy,# lz4-256k, lz4-1M, lz4, flate, zstd)# CLI flag: -ingester.chunk-encoding[chunk_encoding:<string> | default = "gzip"]# The maximum duration of a timeseries chunk in memory. If a timeseries runs for# longer than this, the current chunk will be flushed to the store and a new# chunk created.# CLI flag: -ingester.max-chunk-age[max_chunk_age:<duration> | default = 2h]# Forget about ingesters having heartbeat timestamps older than# `ring.kvstore.heartbeat_timeout`. This is equivalent to clicking on the# `/ring` `forget` button in the UI: the ingester is removed from the ring. This# is a useful setting when you are sure that an unhealthy node won't return. An# example is when not using stateful sets or the equivalent. Use# `memberlist.rejoin_interval` > 0 to handle network partition cases when using# a memberlist.# CLI flag: -ingester.autoforget-unhealthy[autoforget_unhealthy:<boolean> | default = false]# Parameters used to synchronize ingesters to cut chunks at the same moment.# Sync period is used to roll over incoming entry to a new chunk. If chunk's# utilization isn't high enough (eg. less than 50% when sync_min_utilization is# set to 0.5), then this chunk rollover doesn't happen.# CLI flag: -ingester.sync-period[sync_period:<duration> | default = 0s]# Minimum utilization of chunk when doing synchronization.# CLI flag: -ingester.sync-min-utilization[sync_min_utilization:<float> | default = 0]# The maximum number of errors a stream will report to the user when a push# fails. 0 to make unlimited.# CLI flag: -ingester.max-ignored-stream-errors[max_returned_stream_errors:<int> | default = 10]# How far back should an ingester be allowed to query the store for data, for# use only with boltdb-shipper/tsdb index and filesystem object store. -1 for# infinite.# CLI flag: -ingester.query-store-max-look-back-period[query_store_max_look_back_period:<duration> | default = 0s]# The ingester WAL (Write Ahead Log) records incoming logs and stores them on# the local file systems in order to guarantee persistence of acknowledged data# in the event of a process crash.wal:# Enable writing of ingested data into WAL.# CLI flag: -ingester.wal-enabled[enabled:<boolean> | default = true]# Directory where the WAL data is stored and/or recovered from.# CLI flag: -ingester.wal-dir[dir:<string> | default = "wal"]# Interval at which checkpoints should be created.# CLI flag: -ingester.checkpoint-duration[checkpoint_duration:<duration> | default = 5m]# When WAL is enabled, should chunks be flushed to long-term storage on# shutdown.# CLI flag: -ingester.flush-on-shutdown[flush_on_shutdown:<boolean> | default = false]# Maximum memory size the WAL may use during replay. After hitting this, it# will flush data to storage before continuing. A unit suffix (KB, MB, GB) may# be applied.# CLI flag: -ingester.wal-replay-memory-ceiling[replay_memory_ceiling:<int> | default = 4GB]# Shard factor used in the ingesters for the in process reverse index. This MUST# be evenly divisible by ALL schema shard factors or Loki will not start.# CLI flag: -ingester.index-shards[index_shards:<int> | default = 32]# Maximum number of dropped streams to keep in memory during tailing.# CLI flag: -ingester.tailer.max-dropped-streams[max_dropped_streams:<int> | default = 10]
# Maximum duration for which the live tailing requests are served.# CLI flag: -querier.tail-max-duration[tail_max_duration:<duration> | default = 1h]# Time to wait before sending more than the minimum successful query requests.# CLI flag: -querier.extra-query-delay[extra_query_delay:<duration> | default = 0s]# Maximum lookback beyond which queries are not sent to ingester. 0 means all# queries are sent to ingester.# CLI flag: -querier.query-ingesters-within[query_ingesters_within:<duration> | default = 3h]engine:# Deprecated: Use querier.query-timeout instead. Timeout for query execution.# CLI flag: -querier.engine.timeout[timeout:<duration> | default = 5m]# The maximum amount of time to look back for log lines. Used only for instant# log queries.# CLI flag: -querier.engine.max-lookback-period[max_look_back_period:<duration> | default = 30s]# The maximum number of concurrent queries allowed.# CLI flag: -querier.max-concurrent[max_concurrent:<int> | default = 10]# Only query the store, and not attempt any ingesters. This is useful for# running a standalone querier pool operating only against stored data.# CLI flag: -querier.query-store-only[query_store_only:<boolean> | default = false]# When true, queriers only query the ingesters, and not stored data. This is# useful when the object store is unavailable.# CLI flag: -querier.query-ingester-only[query_ingester_only:<boolean> | default = false]# When true, allow queries to span multiple tenants.# CLI flag: -querier.multi-tenant-queries-enabled[multi_tenant_queries_enabled:<boolean> | default = false]# When true, querier limits sent via a header are enforced.# CLI flag: -querier.per-request-limits-enabled[per_request_limits_enabled:<boolean> | default = false]
# URL of alerts return path.# CLI flag: -ruler.external.url[external_url:<url>]# Labels to add to all alerts.[external_labels:<list of Labels>]# The grpc_client block configures the gRPC client used to communicate between# two Loki components.# The CLI flags prefix for this block configuration is: ruler.client[ruler_client:<grpc_client>]# How frequently to evaluate rules.# CLI flag: -ruler.evaluation-interval[evaluation_interval:<duration> | default = 1m]# How frequently to poll for rule changes.# CLI flag: -ruler.poll-interval[poll_interval:<duration> | default = 1m]# Deprecated: Use -ruler-storage. CLI flags and their respective YAML config# options instead.storage:# Method to use for backend rule storage (configdb, azure, gcs, s3, swift,# local, bos)# CLI flag: -ruler.storage.type[type:<string> | default = ""]# Configures backend rule storage for Azure.# The CLI flags prefix for this block configuration is: ruler.storage[azure:<azure_storage_config>]# Configures backend rule storage for AlibabaCloud Object Storage (OSS).# The CLI flags prefix for this block configuration is: ruler[alibabacloud:<alibabacloud_storage_config>]# Configures backend rule storage for GCS.# The CLI flags prefix for this block configuration is: ruler.storage[gcs:<gcs_storage_config>]# Configures backend rule storage for S3.# The CLI flags prefix for this block configuration is: ruler[s3:<s3_storage_config>]# Configures backend rule storage for Baidu Object Storage (BOS).# The CLI flags prefix for this block configuration is: ruler.storage[bos:<bos_storage_config>]# Configures backend rule storage for Swift.# The CLI flags prefix for this block configuration is: ruler.storage[swift:<swift_storage_config>]# Configures backend rule storage for a local file system directory.local:# Directory to scan for rules# CLI flag: -ruler.storage.local.directory[directory:<string> | default = ""]# File path to store temporary rule files.# CLI flag: -ruler.rule-path[rule_path:<string> | default = "/rules"]# Comma-separated list of Alertmanager URLs to send notifications to. Each# Alertmanager URL is treated as a separate group in the configuration. Multiple# Alertmanagers in HA per group can be supported by using DNS resolution via# '-ruler.alertmanager-discovery'.# CLI flag: -ruler.alertmanager-url[alertmanager_url:<string> | default = ""]# Use DNS SRV records to discover Alertmanager hosts.# CLI flag: -ruler.alertmanager-discovery[enable_alertmanager_discovery:<boolean> | default = false]# How long to wait between refreshing DNS resolutions of Alertmanager hosts.# CLI flag: -ruler.alertmanager-refresh-interval[alertmanager_refresh_interval:<duration> | default = 1m]# If enabled requests to Alertmanager will utilize the V2 API.# CLI flag: -ruler.alertmanager-use-v2[enable_alertmanager_v2:<boolean> | default = false]# List of alert relabel configs.[alert_relabel_configs:<relabel_config...>]# Capacity of the queue for notifications to be sent to the Alertmanager.# CLI flag: -ruler.notification-queue-capacity[notification_queue_capacity:<int> | default = 10000]# HTTP timeout duration when sending notifications to the Alertmanager.# CLI flag: -ruler.notification-timeout[notification_timeout:<duration> | default = 10s]alertmanager_client:# Path to the client certificate file, which will be used for authenticating# with the server. Also requires the key path to be configured.# CLI flag: -ruler.alertmanager-client.tls-cert-path[tls_cert_path:<string> | default = ""]# Path to the key file for the client certificate. Also requires the client# certificate to be configured.# CLI flag: -ruler.alertmanager-client.tls-key-path[tls_key_path:<string> | default = ""]# Path to the CA certificates file to validate server certificate against. If# not set, the host's root CA certificates are used.# CLI flag: -ruler.alertmanager-client.tls-ca-path[tls_ca_path:<string> | default = ""]# Override the expected name on the server certificate.# CLI flag: -ruler.alertmanager-client.tls-server-name[tls_server_name:<string> | default = ""]# Skip validating server certificate.# CLI flag: -ruler.alertmanager-client.tls-insecure-skip-verify[tls_insecure_skip_verify:<boolean> | default = false]# Override the default cipher suite list (separated by commas). Allowed# values:# # Secure Ciphers:# - TLS_RSA_WITH_AES_128_CBC_SHA# - TLS_RSA_WITH_AES_256_CBC_SHA# - TLS_RSA_WITH_AES_128_GCM_SHA256# - TLS_RSA_WITH_AES_256_GCM_SHA384# - TLS_AES_128_GCM_SHA256# - TLS_AES_256_GCM_SHA384# - TLS_CHACHA20_POLY1305_SHA256# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA# - TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA# - TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA# - TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256# - TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384# - TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256# - TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384# - TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256# - TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256# # Insecure Ciphers:# - TLS_RSA_WITH_RC4_128_SHA# - TLS_RSA_WITH_3DES_EDE_CBC_SHA# - TLS_RSA_WITH_AES_128_CBC_SHA256# - TLS_ECDHE_ECDSA_WITH_RC4_128_SHA# - TLS_ECDHE_RSA_WITH_RC4_128_SHA# - TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256# CLI flag: -ruler.alertmanager-client.tls-cipher-suites[tls_cipher_suites:<string> | default = ""]# Override the default minimum TLS version. Allowed values: VersionTLS10,# VersionTLS11, VersionTLS12, VersionTLS13# CLI flag: -ruler.alertmanager-client.tls-min-version[tls_min_version:<string> | default = ""]# HTTP Basic authentication username. It overrides the username set in the URL# (if any).# CLI flag: -ruler.alertmanager-client.basic-auth-username[basic_auth_username:<string> | default = ""]# HTTP Basic authentication password. It overrides the password set in the URL# (if any).# CLI flag: -ruler.alertmanager-client.basic-auth-password[basic_auth_password:<string> | default = ""]# HTTP Header authorization type (default: Bearer).# CLI flag: -ruler.alertmanager-client.type[type:<string> | default = "Bearer"]# HTTP Header authorization credentials.# CLI flag: -ruler.alertmanager-client.credentials[credentials:<string> | default = ""]# HTTP Header authorization credentials file.# CLI flag: -ruler.alertmanager-client.credentials-file[credentials_file:<string> | default = ""]# Max time to tolerate outage for restoring "for" state of alert.# CLI flag: -ruler.for-outage-tolerance[for_outage_tolerance:<duration> | default = 1h]# Minimum duration between alert and restored "for" state. This is maintained# only for alerts with configured "for" time greater than the grace period.# CLI flag: -ruler.for-grace-period[for_grace_period:<duration> | default = 10m]# Minimum amount of time to wait before resending an alert to Alertmanager.# CLI flag: -ruler.resend-delay[resend_delay:<duration> | default = 1m]# Distribute rule evaluation using ring backend.# CLI flag: -ruler.enable-sharding[enable_sharding:<boolean> | default = false]# The sharding strategy to use. Supported values are: default, shuffle-sharding.# CLI flag: -ruler.sharding-strategy[sharding_strategy:<string> | default = "default"]# The sharding algorithm to use for deciding how rules & groups are sharded.# Supported values are: by-group, by-rule.# CLI flag: -ruler.sharding-algo[sharding_algo:<string> | default = "by-group"]# Time to spend searching for a pending ruler when shutting down.# CLI flag: -ruler.search-pending-for[search_pending_for:<duration> | default = 5m]# Ring used by Loki ruler. The CLI flags prefix for this block configuration is# 'ruler.ring'.ring:kvstore:# Backend storage to use for the ring. Supported values are: consul, etcd,# inmemory, memberlist, multi.# CLI flag: -ruler.ring.store[store:<string> | default = "consul"]# The prefix for the keys in the store. Should end with a /.# CLI flag: -ruler.ring.prefix[prefix:<string> | default = "rulers/"]# Configuration for a Consul client. Only applies if the selected kvstore is# consul.# The CLI flags prefix for this block configuration is: ruler.ring[consul:<consul>]# Configuration for an ETCD v3 client. Only applies if the selected kvstore# is etcd.# The CLI flags prefix for this block configuration is: ruler.ring[etcd:<etcd>]multi:# Primary backend storage used by multi-client.# CLI flag: -ruler.ring.multi.primary[primary:<string> | default = ""]# Secondary backend storage used by multi-client.# CLI flag: -ruler.ring.multi.secondary[secondary:<string> | default = ""]# Mirror writes to secondary store.# CLI flag: -ruler.ring.multi.mirror-enabled[mirror_enabled:<boolean> | default = false]# Timeout for storing value to secondary store.# CLI flag: -ruler.ring.multi.mirror-timeout[mirror_timeout:<duration> | default = 2s]# Interval between heartbeats sent to the ring. 0 = disabled.# CLI flag: -ruler.ring.heartbeat-period[heartbeat_period:<duration> | default = 5s]# The heartbeat timeout after which ruler ring members are considered# unhealthy within the ring. 0 = never (timeout disabled).# CLI flag: -ruler.ring.heartbeat-timeout[heartbeat_timeout:<duration> | default = 1m]# Name of network interface to read addresses from.# CLI flag: -ruler.ring.instance-interface-names[instance_interface_names:<list of strings> | default = [<private network interfaces>]]# The number of tokens the lifecycler will generate and put into the ring if# it joined without transferring tokens from another lifecycler.# CLI flag: -ruler.ring.num-tokens[num_tokens:<int> | default = 128]# Period with which to attempt to flush rule groups.# CLI flag: -ruler.flush-period[flush_period:<duration> | default = 1m]# Enable the ruler API.# CLI flag: -ruler.enable-api[enable_api:<boolean> | default = true]# Comma separated list of tenants whose rules this ruler can evaluate. If# specified, only these tenants will be handled by ruler, otherwise this ruler# can process rules from all tenants. Subject to sharding.# CLI flag: -ruler.enabled-tenants[enabled_tenants:<string> | default = ""]# Comma separated list of tenants whose rules this ruler cannot evaluate. If# specified, a ruler that would normally pick the specified tenant(s) for# processing will ignore them instead. Subject to sharding.# CLI flag: -ruler.disabled-tenants[disabled_tenants:<string> | default = ""]# Report the wall time for ruler queries to complete as a per user metric and as# an info level log message.# CLI flag: -ruler.query-stats-enabled[query_stats_enabled:<boolean> | default = false]# Disable the rule_group label on exported metrics.# CLI flag: -ruler.disable-rule-group-label[disable_rule_group_label:<boolean> | default = false]wal:# The directory in which to write tenant WAL files. Each tenant will have its# own directory one level below this directory.# CLI flag: -ruler.wal.dir[dir:<string> | default = "ruler-wal"]# Frequency with which to run the WAL truncation process.# CLI flag: -ruler.wal.truncate-frequency[truncate_frequency:<duration> | default = 1h]# Minimum age that samples must exist in the WAL before being truncated.# CLI flag: -ruler.wal.min-age[min_age:<duration> | default = 5m]# Maximum age that samples must exist in the WAL before being truncated.# CLI flag: -ruler.wal.max-age[max_age:<duration> | default = 4h]wal_cleaner:# The minimum age of a WAL to consider for cleaning.# CLI flag: -ruler.wal-cleaner.min-age[min_age:<duration> | default = 12h]# Deprecated: CLI flag -ruler.wal-cleaer.period.# Use -ruler.wal-cleaner.period instead.# # How often to run the WAL cleaner. 0 = disabled.# CLI flag: -ruler.wal-cleaner.period[period:<duration> | default = 0s]# Remote-write configuration to send rule samples to a Prometheus remote-write# endpoint.remote_write:# Deprecated: Use 'clients' instead. Configure remote write client.[client:<RemoteWriteConfig>]# Configure remote write clients. A map with remote client id as key.[clients:<map of string to RemoteWriteConfig>]# Enable remote-write functionality.# CLI flag: -ruler.remote-write.enabled[enabled:<boolean> | default = false]# Minimum period to wait between refreshing remote-write reconfigurations.# This should be greater than or equivalent to# -limits.per-user-override-period.# CLI flag: -ruler.remote-write.config-refresh-period[config_refresh_period:<duration> | default = 10s]
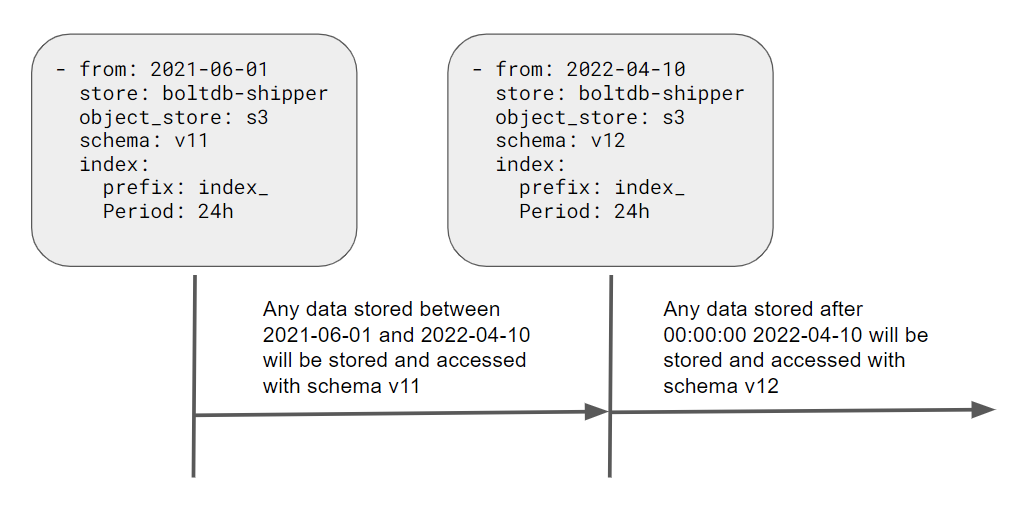
# The date of the first day that index buckets should be created. Use a date in# the past if this is your only period_config, otherwise use a date when you# want the schema to switch over. In YYYY-MM-DD format, for example: 2018-04-15.[from:<daytime>]# store and object_store below affect which <storage_config> key is used.# Which store to use for the index. Either aws, aws-dynamo, gcp, bigtable,# bigtable-hashed, cassandra, boltdb or boltdb-shipper.[store:<string> | default = ""]# Which store to use for the chunks. Either aws, azure, gcp, bigtable, gcs,# cassandra, swift, filesystem or a named_store (refer to named_stores_config).# If omitted, defaults to the same value as store.[object_store:<string> | default = ""]# The schema version to use, current recommended schema is v11.[schema:<string> | default = ""]# Configures how the index is updated and stored.index:# Table prefix for all period tables.[prefix:<string> | default = ""]# Table period.[period:<duration>]# A map to be added to all managed tables.[tags:<map of string to string>]# Configured how the chunks are updated and stored.chunks:# Table prefix for all period tables.[prefix:<string> | default = ""]# Table period.[period:<duration>]# A map to be added to all managed tables.[tags:<map of string to string>]# How many shards will be created. Only used if schema is v10 or greater.[row_shards:<int>]