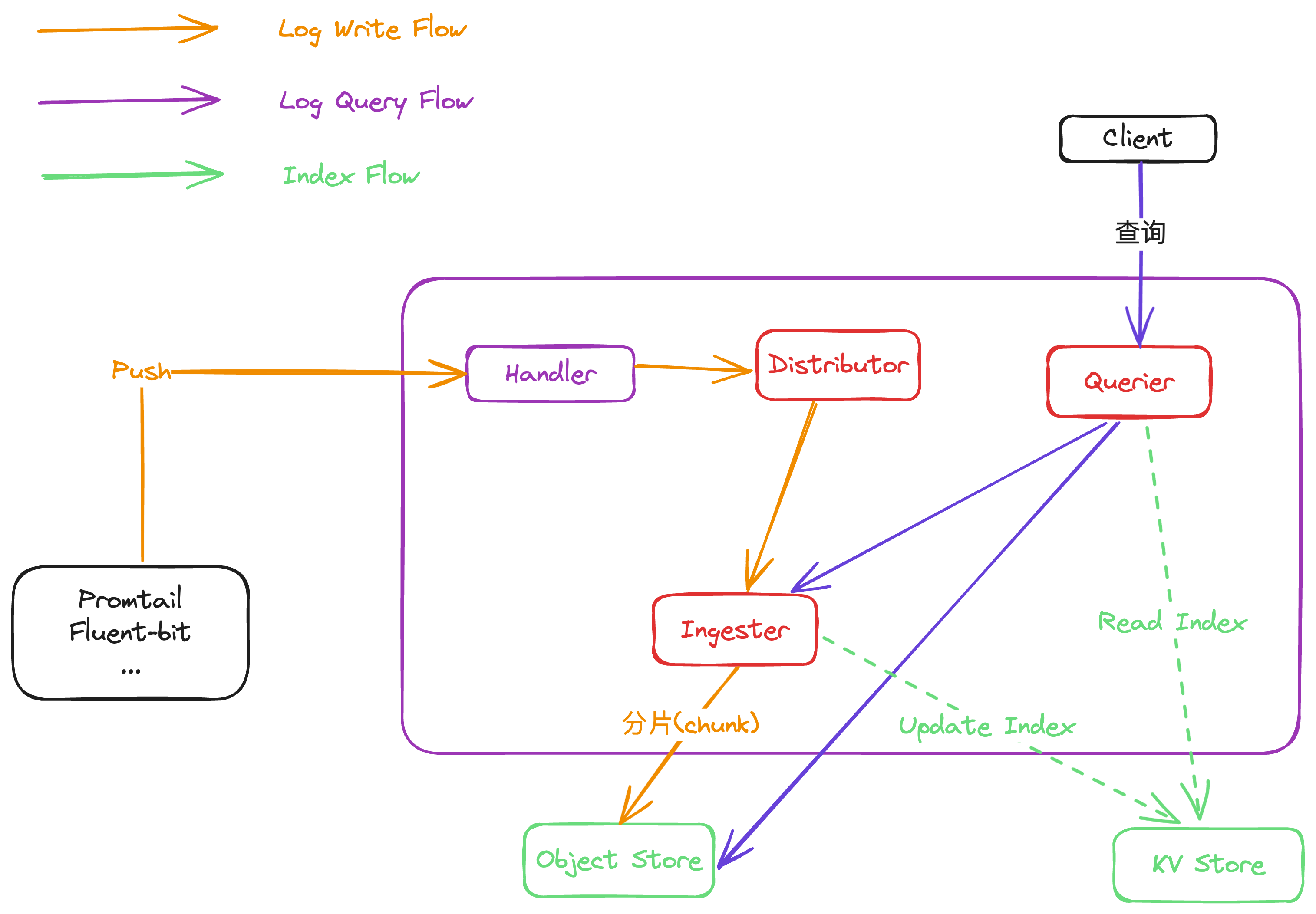
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
| func (d *Distributor) Push(ctx context.Context, req *logproto.PushRequest) (*logproto.PushResponse, error) {
// 首先从上下文中获取租户ID,然后检查请求对象req是否为空,如果为空则直接返回一个空的响应对象
tenantID, err := tenant.TenantID(ctx)
if err != nil {
return nil, err
}
// Return early if request does not contain any streams
if len(req.Streams) == 0 {
return &logproto.PushResponse{}, nil
}
// First we flatten out the request into a list of samples.
// We use the heuristic of 1 sample per TS to size the array.
// We also work out the hash value at the same time.
// 将每个流数据转换为一个streamTracker对象,并计算出流数据的哈希值。
// 函数还会对流数据进行验证,如果验证失败则会记录相关信息并继续处理下一个流数据
streams := make([]streamTracker, 0, len(req.Streams))
keys := make([]uint32, 0, len(req.Streams))
validatedLineSize := 0
validatedLineCount := 0
var validationErr error
validationContext := d.validator.getValidationContextForTime(time.Now(), tenantID)
// 遍历请求中的每一个Stream集
for _, stream := range req.Streams {
// Return early if stream does not contain any entries
if len(stream.Entries) == 0 {
continue
}
// Truncate first so subsequent steps have consistent line lengths
d.truncateLines(validationContext, &stream)
// 解析Stream中的labels计算出流数据的哈希值
stream.Labels, stream.Hash, err = d.parseStreamLabels(validationContext, stream.Labels, &stream)
if err != nil {
validationErr = err
validation.DiscardedSamples.WithLabelValues(validation.InvalidLabels, tenantID).Add(float64(len(stream.Entries)))
bytes := 0
for _, e := range stream.Entries {
bytes += len(e.Line)
}
validation.DiscardedBytes.WithLabelValues(validation.InvalidLabels, tenantID).Add(float64(bytes))
continue
}
// 将流数据进行分片,并将分片后的数据发送到不同的ingesters
n := 0
streamSize := 0
for _, entry := range stream.Entries {
if err := d.validator.ValidateEntry(validationContext, stream.Labels, entry); err != nil {
validationErr = err
continue
}
stream.Entries[n] = entry
// If configured for this tenant, increment duplicate timestamps. Note, this is imperfect
// since Loki will accept out of order writes it doesn't account for separate
// pushes with overlapping time ranges having entries with duplicate timestamps
if validationContext.incrementDuplicateTimestamps && n != 0 {
// Traditional logic for Loki is that 2 lines with the same timestamp and
// exact same content will be de-duplicated, (i.e. only one will be stored, others dropped)
// To maintain this behavior, only increment the timestamp if the log content is different
if stream.Entries[n-1].Line != entry.Line {
stream.Entries[n].Timestamp = maxT(entry.Timestamp, stream.Entries[n-1].Timestamp.Add(1*time.Nanosecond))
}
}
n++
validatedLineSize += len(entry.Line)
validatedLineCount++
streamSize += len(entry.Line)
}
stream.Entries = stream.Entries[:n]
shardStreamsCfg := d.validator.Limits.ShardStreams(tenantID)
if shardStreamsCfg.Enabled {
derivedKeys, derivedStreams := d.shardStream(stream, streamSize, tenantID)
keys = append(keys, derivedKeys...)
streams = append(streams, derivedStreams...)
} else {
keys = append(keys, util.TokenFor(tenantID, stream.Labels))
streams = append(streams, streamTracker{stream: stream})
}
}
// Return early if none of the streams contained entries
if len(streams) == 0 {
return &logproto.PushResponse{}, validationErr
}
now := time.Now()
// 根据配置信息进行限流,并返回429响应
if !d.ingestionRateLimiter.AllowN(now, tenantID, validatedLineSize) {
// Return a 429 to indicate to the client they are being rate limited
validation.DiscardedSamples.WithLabelValues(validation.RateLimited, tenantID).Add(float64(validatedLineCount))
validation.DiscardedBytes.WithLabelValues(validation.RateLimited, tenantID).Add(float64(validatedLineSize))
return nil, httpgrpc.Errorf(http.StatusTooManyRequests, validation.RateLimitedErrorMsg, tenantID, int(d.ingestionRateLimiter.Limit(now, tenantID)), validatedLineCount, validatedLineSize)
}
const maxExpectedReplicationSet = 5 // typical replication factor 3 plus one for inactive plus one for luck
var descs [maxExpectedReplicationSet]ring.InstanceDesc
// 根据ingesters的数量创建一个map,用于存储每个ingester对应的流数据
streamsByIngester := map[string][]*streamTracker{}
ingesterDescs := map[string]ring.InstanceDesc{}
for i, key := range keys {
replicationSet, err := d.ingestersRing.Get(key, ring.WriteNoExtend, descs[:0], nil, nil)
if err != nil {
return nil, err
}
streams[i].minSuccess = len(replicationSet.Instances) - replicationSet.MaxErrors
streams[i].maxFailures = replicationSet.MaxErrors
for _, ingester := range replicationSet.Instances {
streamsByIngester[ingester.Addr] = append(streamsByIngester[ingester.Addr], &streams[i])
ingesterDescs[ingester.Addr] = ingester
}
}
tracker := pushTracker{
done: make(chan struct{}, 1), // buffer avoids blocking if caller terminates - sendSamples() only sends once on each
err: make(chan error, 1),
}
tracker.streamsPending.Store(int32(len(streams)))
// 根据配置信息和流数据的哈希值选择一个ingester,并将流数据发送到该ingester中
for ingester, streams := range streamsByIngester {
go func(ingester ring.InstanceDesc, samples []*streamTracker) {
// Use a background context to make sure all ingesters get samples even if we return early
localCtx, cancel := context.WithTimeout(context.Background(), d.clientCfg.RemoteTimeout)
defer cancel()
localCtx = user.InjectOrgID(localCtx, tenantID)
if sp := opentracing.SpanFromContext(ctx); sp != nil {
localCtx = opentracing.ContextWithSpan(localCtx, sp)
}
d.sendStreams(localCtx, ingester, samples, &tracker)
}(ingesterDescs[ingester], streams)
}
select {
case err := <-tracker.err:
return nil, err
case <-tracker.done:
return &logproto.PushResponse{}, validationErr
case <-ctx.Done():
return nil, ctx.Err()
}
}
|