Loki系统架构
Loki 系统架构
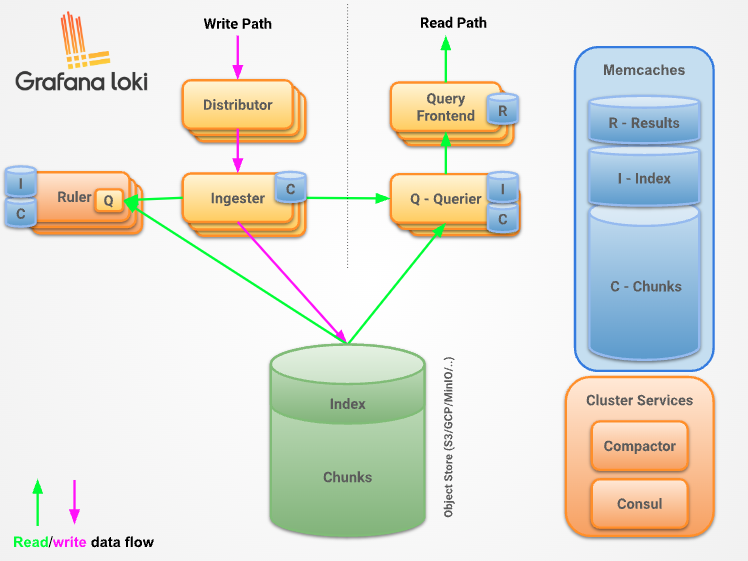
Loki 组件
Distributor (分发器)
Distributor 服务负责处理客户端写入的日志,它本质上是日志数据写入路径中的入口,一旦 Distributor 收到日志数据,会将其拆分为多个批次,然后并行发送给多个 Ingester 。 Distributor 通过 gRPC 与 Ingester 通信,它们都是无状态的,所以可以根据需要扩大或缩小规模。
Validation (校验)
Distributor 第一步是确保所有传入数据均符合规范。这包括检查标签是否是有效的 Prometheus 标签,以及确保时间戳不会太旧或太新,或者日志行不会太长。
Preprocessing (预处理)
规范化标签,对标签进行排序,从而能够准确的命中 cache 和 hash。
Rate limiting (限速)
Distributor 可以根据每个租户的最大比特率对传入日志进行速率限制。 它通过检查每个租户的限制并将其除以当前的 Distributor 数量。 这允许在集群级别为每个租户指定速率限制,并使我们能够向上或向下扩展 Distributor,并相应地调整每个 Distributor 的限制
Forwarding (转发)
Distributor 验证通过后,它就会将数据转发到最终负责确认写入的 Ingester 组件。
Replication factor (副本)
为了减少在任何单个 Ingester 上丢失数据的机会,Distributor 会将写入转发到它们的 replication_factor 。默认 3 副本。副本允许 Ingester 重新启动和推出而不会导致写入失败,并在某些情况下增加额外的数据丢失保护。
floor(replication_factor / 2) + 1
Hashing
Distributor 将一致性Hash和可配置的复制因子结合使用,以确定 Ingester 服务的哪些实例应该接收指定的数据流。
流是一组与租户和唯一标签集关联的日志,使用租户 ID 和标签集对流进行 hash 处理,然后使用哈希查询要发送流的 Ingester
Quorum consistency
Ingester
Ingester 服务负责将日志数据写入存储后端(DynamoDB、S3、Cassandra )。此外 Ingester 会验证摄取的日志行是否按照时间戳递增的顺序接收的(即每条日志的时间戳都比前面的日志晚一些),当 Ingester 收到不符合这个顺序的日志时,该日志行会被拒绝并返回一个错误。
如果传入的行与之前收到的行完全匹配(与之前的时间戳和日志文本都匹配),传入的行将被视为完全重复并被忽略。
如果传入的行与前一行的时间戳相同,但内容不同,则接受该日志行,表示同一时间戳有两个不同的日志行是可能的。
Querier (查询器)
Querier 接收日志数据查询、聚合统计请求,使用 LogQL 查询语言处理查询,从 ingester 和长期存储中获取日志。
查询器查询所有 ingester 的内存数据,然后再到后端存储运行相同的查询。由于复制因子,查询器有可能会收到重复的数据。为了解决这个问题,查询器在内部对具有相同纳秒时间戳、标签集和日志信息的数据进行重复数据删除。
Query frontend
Query Frontend 查询前端是一个可选的服务,可以用来加速读取路径。当查询前端就位时,将传入的查询请求定向到查询前端,而不是 querier, 为了执行实际的查询,群集中仍需要 querier 服务。
查询前端在内部执行一些查询调整,并在内部队列中保存查询。querier 作为 workers 从队列中提取作业,执行它们,并将它们返回到查询前端进行汇总。querier 需要配置查询前端地址,以便允许它们连接到查询前端。
查询前端是无状态的,然而,由于内部队列的工作方式,建议运行几个查询前台的副本,以获得公平调度的好处,在大多数情况下,两个副本应该足够了。
数据处理流程
数据读取
- 查询器收到一个 HTTP/1 数据请求。
- 查询器将查询传递给内存中数据的所有
Ingester。 Ingester接收读取请求并返回与查询匹配的数据(如果有)。- 如果没有
Ingester返回数据,查询器会从后备存储中延迟加载数据并对其运行查询。 - 查询器遍历所有接收到的数据并删除重复数据,通过 HTTP/1 连接返回一组最终数据。
数据写入

Distributor收到 HTTP/1 请求以存储流数据。- 每个流都使用哈希环进行哈希处理。
Distributor将每个流发送到适当的Ingester及其副本(基于配置的复制因子)。- 每个
Ingester将为流的数据创建一个块或附加到现有块。每个租户和每个标签集的块都是唯一的。 - 分发者通过 HTTP/1 连接以成功代码响应。
部署模式
单体模式
单体模式适用于快速开始体验 Loki 进行实验以及每天最多约 100GB 的小读/写量场景。
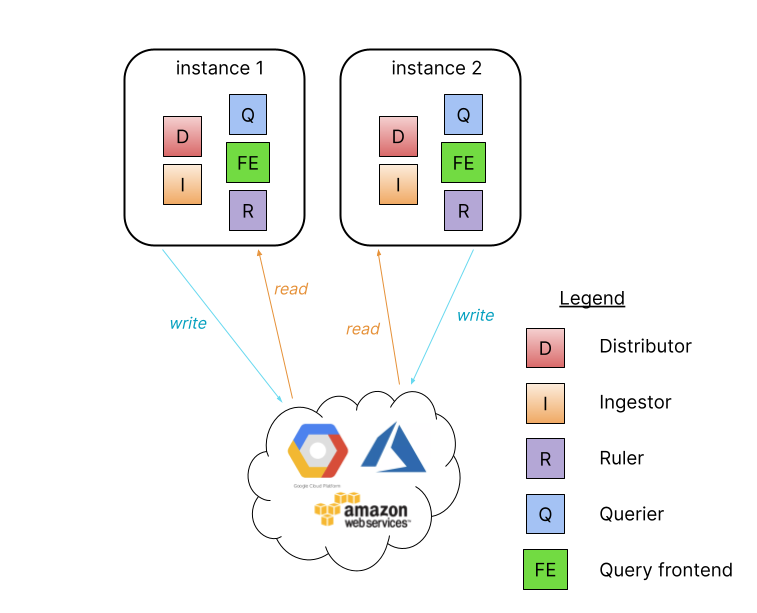
读写分离模式
当日志量每天超过几百 GB,或者希望分离读写,Loki 提供了简单的读写分离可扩展部署模式。这种部署模式可以扩展到每天数 TB 的日志。
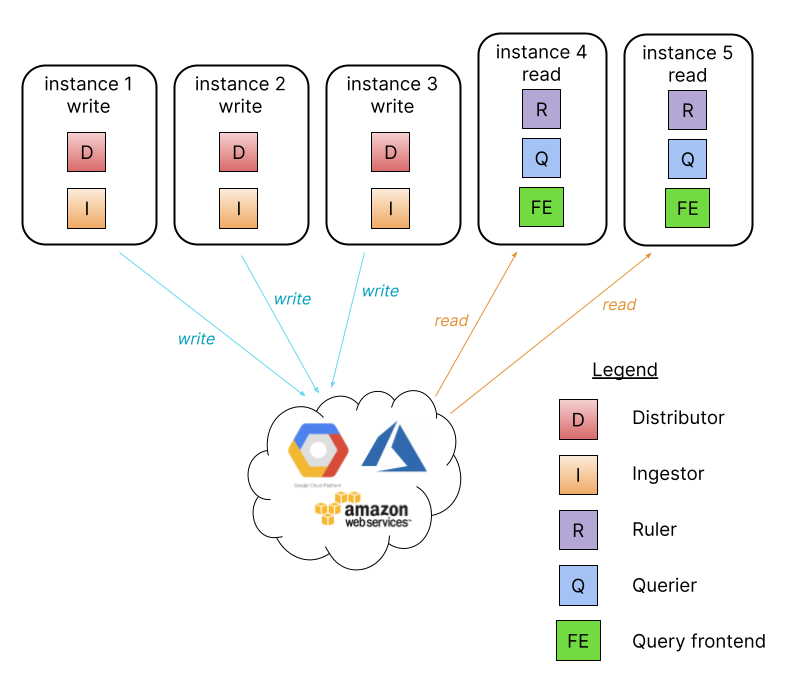
微服务模式
每个组件独立部署,适用于超大型日志收集。